- Lessons from the Field: An Adaptable Lifecycle Approach to Applied Dialogue Summarization
Kushal Chawla, Chenyang Zhu, Pengshan Cai, Sangwoo Cho, Scott Novotney, Ayushman Singh, Jonah Lewis, Keasha Safewright, Alfy Samuel, Erin Babinsky, Shi-Xiong Zhang, Sambit Sahu
EACL 2026
Paper
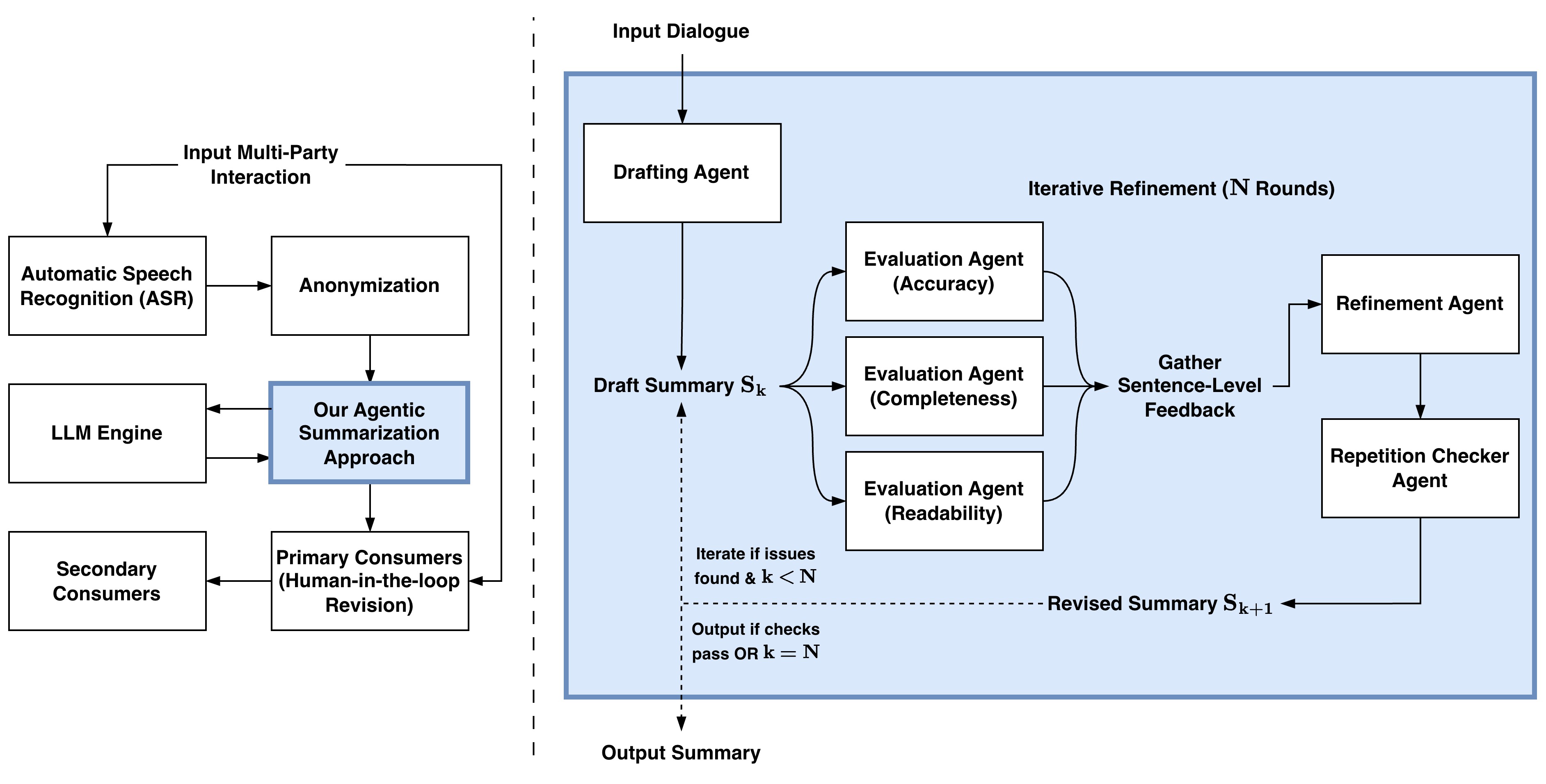
Summarization of multi-party dialogues is a critical capability in industry, enhancing knowledge transfer and operational effectiveness across many domains. However, automatically generating high-quality summaries is challenging, as the ideal summary must satisfy a set of complex, multifaceted requirements. While summarization has received immense attention in research, prior work has primarily utilized static datasets and benchmarks, a condition rare in practical scenarios where requirements inevitably evolve. In this work, we present an industry case study on developing an agentic system to summarize multi-party interactions. We share practical insights spanning the full development lifecycle to guide practitioners in building reliable, adaptable summarization systems, as well as to inform future research, covering: 1) robust methods for evaluation despite evolving requirements and task subjectivity, 2) component-wise optimization enabled by the task decomposition inherent in an agentic architecture, 3) the impact of upstream data bottlenecks, and 4) the realities of vendor lock-in due to the poor transferability of LLM prompts.
- RAFFLES: Reasoning-based Attribution of Faults for LLM Systems
Chenyang Zhu, Spencer Hong, Jingyu Wu, Kushal Chawla, Charlotte Tang, Youbing Yin, Nathan Wolfe, Erin Babinsky, Daben Liu
EACL 2026
Paper
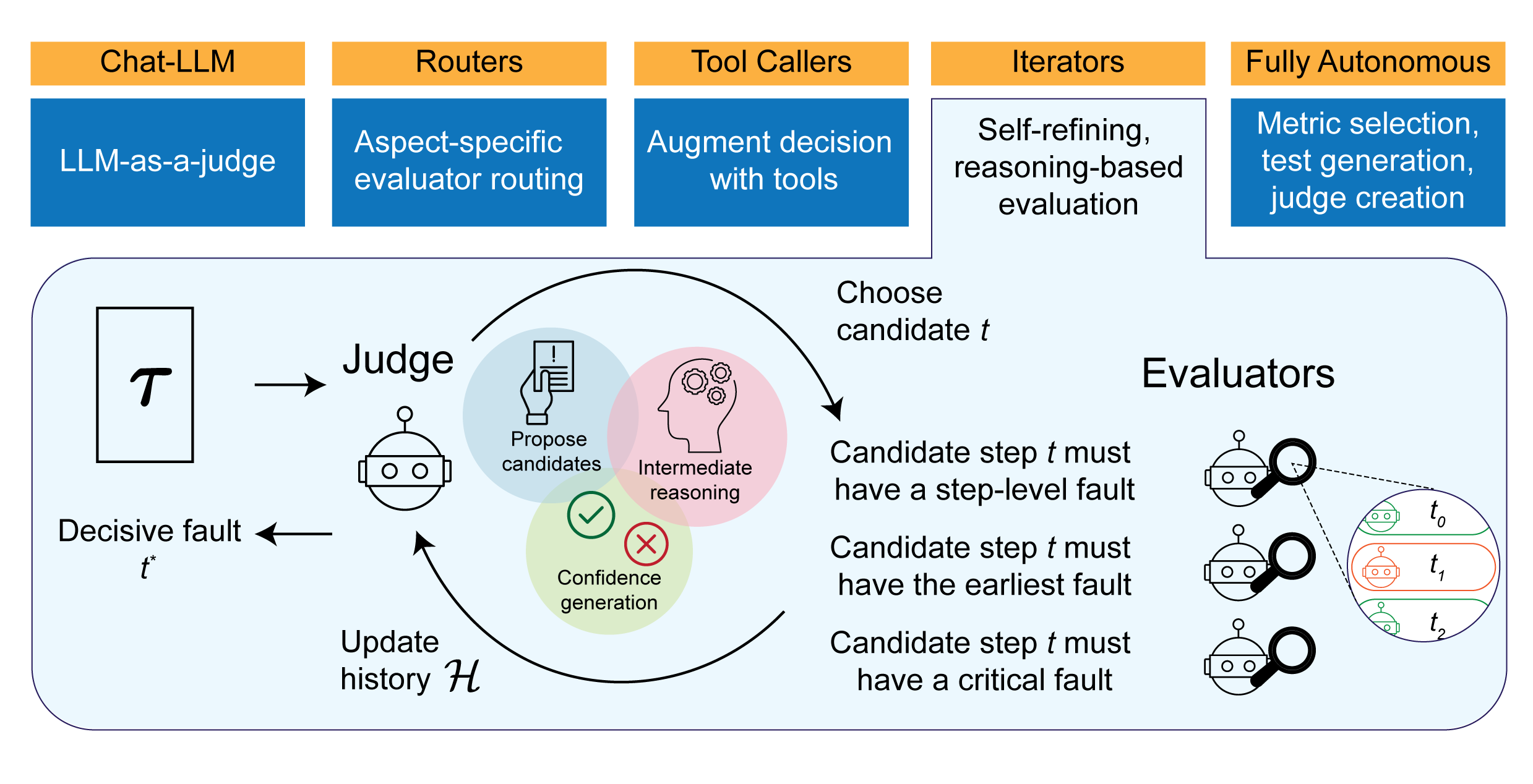
The advent of complex, interconnected long-horizon LLM systems has made it incredibly tricky to identify where and when these systems break down. Evaluation capabilities that currently exist today are limited in that they often focus on simple metrics, end-to-end outcomes, and are dependent on the perspectives of humans. In order to match the increasing complexity of these many component systems, evaluation frameworks must also be able to reason, probe, iterate, and understand the nuanced logic passing through these systems. In this paper, we present RAFFLES, an offline evaluation architecture that incorporates iterative reasoning. Specifically, RAFFLES operates as an iterative, multi-component pipeline, using a central Judge to systematically identify faults and a set of specialized Evaluators to assess the quality of the candidate faults as well as the rationale of the Judge. We evaluated RAFFLES with several benchmarks: the Who&When datasets to identify step-level faults in multi-agent systems and the ReasonEval datasets to diagnose step-level mathematical reasoning errors. RAFFLES outperforms strong baselines, achieving an accuracy of over 20% and 50% on the Who&When Hand-Crafted and Algorithmically-Generated datasets, and over 80% on the ReasonEval datasets. These results demonstrate a key step towards introducing automated fault detection for autonomous systems over labor-intensive manual review.
- FB-RAG: Improving RAG with Forward and Backward Lookup
Kushal Chawla, Alfy Samuel, Anoop Kumar, Daben Liu
AACL 2025
Paper
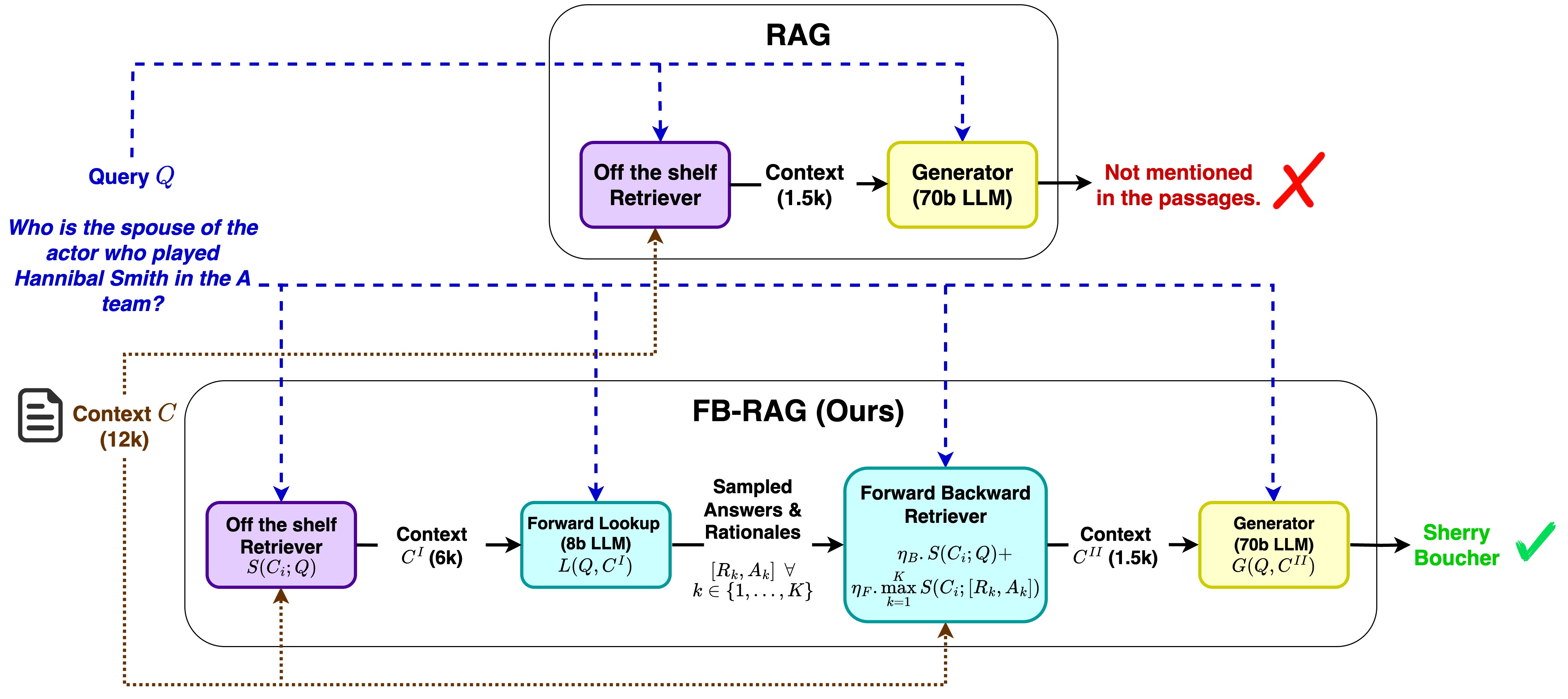
Traditional Retrieval-Augmented Generation (RAG) struggles with complex queries that lack strong signals to retrieve the most relevant context, forcing a trade-off between choosing a small context that misses key information and a large context that confuses the LLM. To address this, we propose Forward-Backward RAG (FB-RAG), a new training-free framework based on a simple yet powerful forward-looking strategy. FB-RAG employs a light-weight LLM to peek into potential future generations, using evidence from multiple sampled outputs to precisely identify the most relevant context for a final, more powerful generator. This improves performance without complex finetuning or Reinforcement Learning common in prior work. Across 9 datasets from LongBench and InfiniteBench, FB-RAG consistently delivers strong results. Further, the performance gains can be achieved with reduced latency due to a shorter, more focused prompt for the powerful generator. On EN.QA dataset, FB-RAG matches the leading baseline with over 48% latency reduction or achieves an 8% performance improvement with a 10% latency reduction. Our analysis finds cases where even when the forward-looking LLM fails to generate correct answers, its attempts are sufficient to guide the final model to an accurate response, demonstrating how smaller LLMs can systematically improve the performance and efficiency of larger ones.
- Be Selfish, But Wisely: Investigating the Impact of Agent Personality in Mixed-Motive Human-Agent Interactions
Kushal Chawla, Ian Wu, Yu Rong, Gale Lucas, Jonathan Gratch
EMNLP 2023
Paper
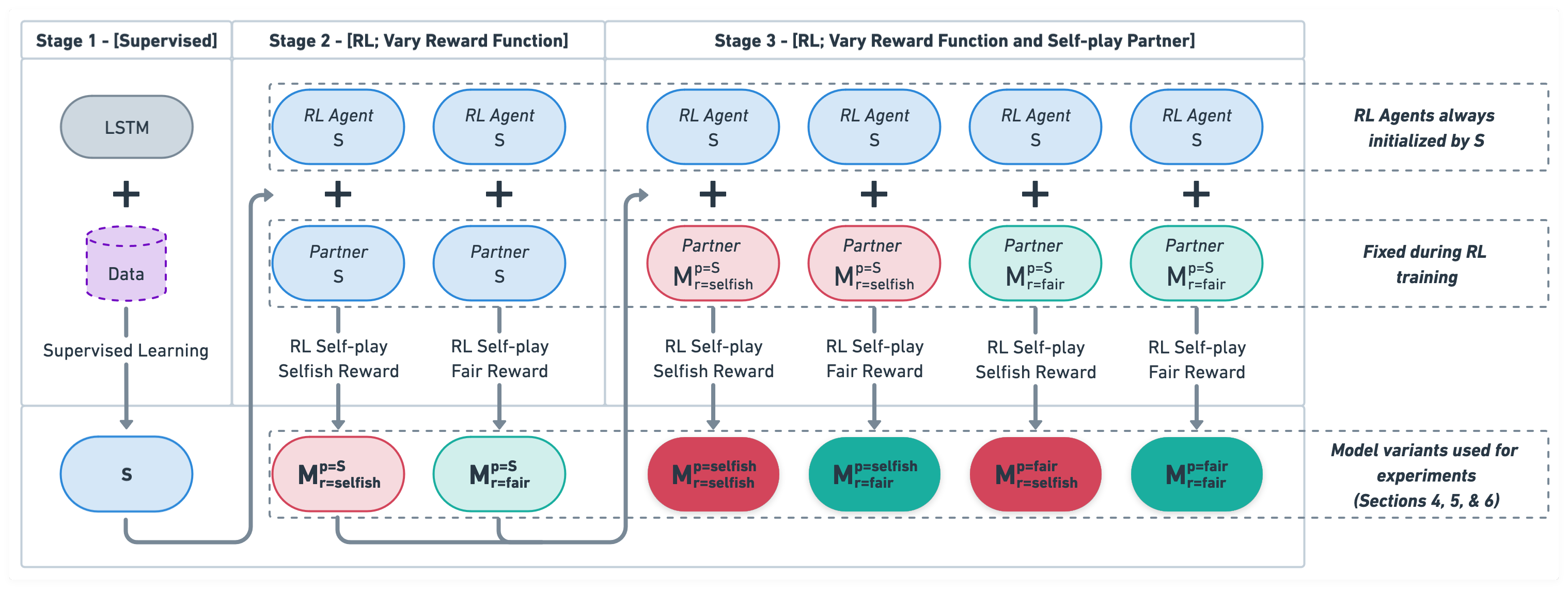
A natural way to design a negotiation dialogue system is via self-play RL: train an agent that learns to maximize its performance by interacting with a simulated user that has been designed to imitate human-human dialogue data. Although this procedure has been adopted in prior work, we find that it results in a fundamentally flawed system that fails to learn the value of compromise in a negotiation, which can often lead to no agreements (i.e., the partner walking away without a deal), ultimately hurting the model’s overall performance. We investigate this observation in the context of DealOrNoDeal task, a multi-issue negotiation over books, hats, and balls. Grounded in negotiation theory from Economics, we modify the training procedure in two novel ways to design agents with diverse personalities and analyze their performance with human partners. We find that although both techniques show promise, a selfish agent, which maximizes its own performance while also avoiding walkaways, performs superior to other variants by implicitly learning to generate value for both itself and the negotiation partner. We discuss the implications of our findings for what it means to be a successful negotiation dialogue system and how these systems should be designed in the future.
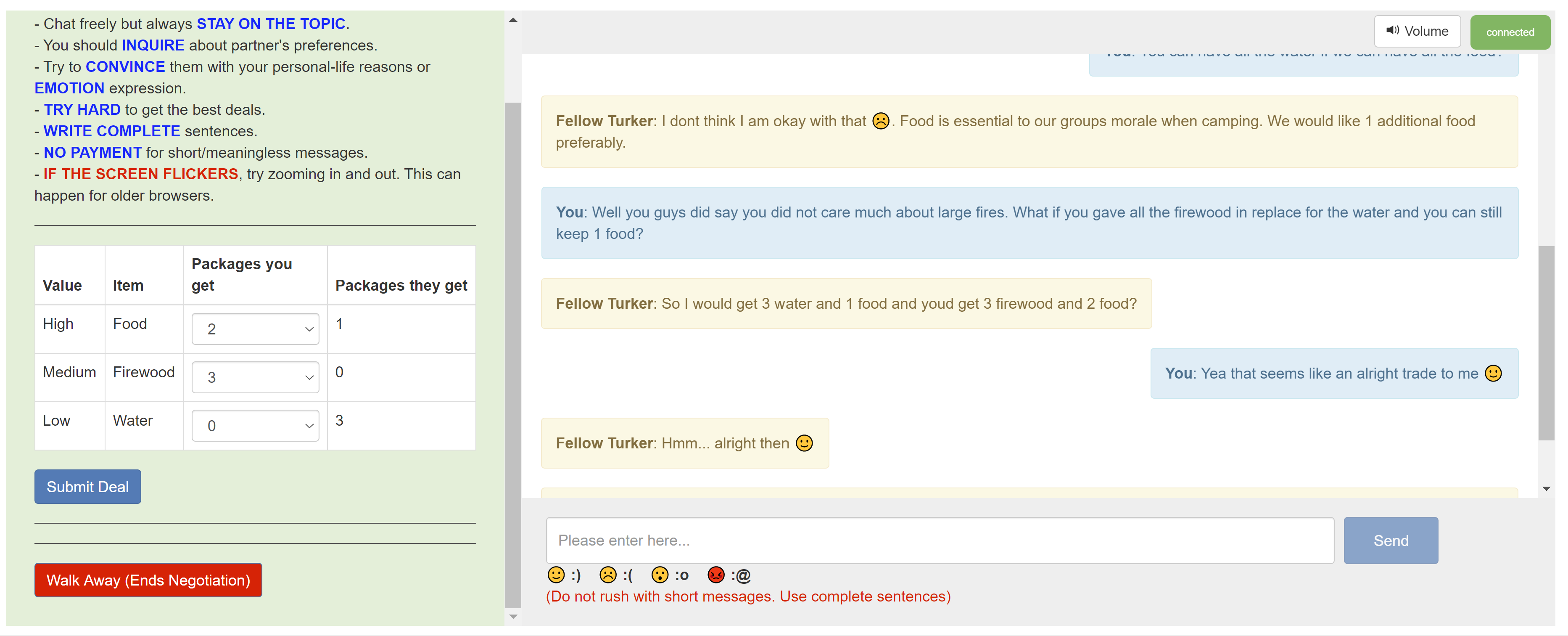
- CaSiNo: A Corpus of Campsite Negotiation Dialogues for Automatic Negotiation Systems
Kushal Chawla, Jaysa Ramirez, Rene Clever, Gale Lucas, Jonathan May, Jonathan Gratch
NAACL 2021
Paper, Dataset
Automated systems that negotiate with humans have broad applications in pedagogy and conversational AI. To advance the development of practical negotiation systems, we present CaSiNo: a novel corpus of over a thousand negotiation dialogues in English. Participants take the role of campsite neighbors and negotiate for food, water, and firewood packages for their upcoming trip. Our design results in diverse and linguistically rich negotiations while maintaining a tractable, closed-domain environment. Inspired by the literature in human-human negotiations, we annotate persuasion strategies and perform correlation analysis to understand how the dialogue behaviors are associated with the negotiation performance. We further propose and evaluate a multi-task framework to recognize these strategies in a given utterance. We find that multi-task learning substantially improves the performance for all strategy labels, especially for the ones that are the most skewed. We release the dataset, annotations, and the code to propel future work in human-machine negotiations.
Browse my Google Scholar profile or my Resume for a complete publication list.